Spark Streaming实时流处理项目实战笔记——从词频统计功能着手入门Spark Streaming
本文共 655 字,大约阅读时间需要 2 分钟。
spark streaming
scalable 可扩展 highthroughput 高吞吐量 fault-tolerant 高容错

Spark一栈式开发
Spark Streaming结合 Sparkcore 实现离线数据和实时统计的整合

spark两种提交作业的方式
1、spark-submit--master local【2】--class xx --name 启动名 位置
spark-submit --master local[2] --calss org.apache.examples.streaming.NetworkWordCount --name NetworkWordCount /opt/spark/spark/examples/jars/spark-examples_2.11-2.4.4.jar

2、spark-shell(测试用途) --master local【2】
spark-shell --master local[2]import org.apache.spark.streaming.{Seconds,StreamingContext}val ssc = new StreamingContext(sc,Seconds(5))val lines = ssc.socketTextStream("hadoop",9999)lines.print()ssc.start()ssc.awaitTermination()

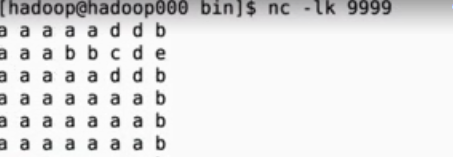
测试通信效果
nc -lk hadoop 9999
转载地址:http://atazi.baihongyu.com/
你可能感兴趣的文章
POJ---3662(Telephone Lines,最短路+二分*好题)
查看>>
L2-007. 家庭房产(并查集)
查看>>
L2-016. 愿天下有情人都是失散多年的兄妹(搜索)
查看>>
L2-019. 悄悄关注
查看>>
POJ 3468 A Simple Problemwith Integers(SplayTree入门题)
查看>>
营业额统计 HYSBZ - 1588 (伸展树简单应用)
查看>>
HDU 1890 Robotic Sort(伸展树---反转应用)
查看>>
POJ 3580 SuperMemo(伸展树的几个基本操作)
查看>>
(十) Web与企业应用中的连接管理
查看>>
(八) 正则表达式
查看>>
一.JavaScript 基础
查看>>
7.ECMAScript 继承
查看>>
HTML DOM
查看>>
AJAX 基础
查看>>
JSON 基础
查看>>
J2EE监听器Listener接口大全[转]
查看>>
cookie、session、sessionid 与jsessionid[转]
查看>>
常见Oracle HINT的用法
查看>>
JAVA中各类CACHE机制实现的比较 [转]
查看>>
PL/SQL Developer技巧
查看>>